Whether you're building a horizontal SaaS tool or a vertical platform for healthcare, logistics, or finance, voice is shifting from a nice-to-have to a must-have. We have already entered the age of talking software.
From AI receptionists to outbound sales agents, machines are now holding real-time, back-and-forth conversations with humans. What used to sound like science fiction is now a competitive edge. But if you've ever tried building a Voice AI product, you'll know it feels deceptively simple at first. You wire up some LLM APIs and get a demo running. But very quickly, you find yourself in a tangle of complexity.
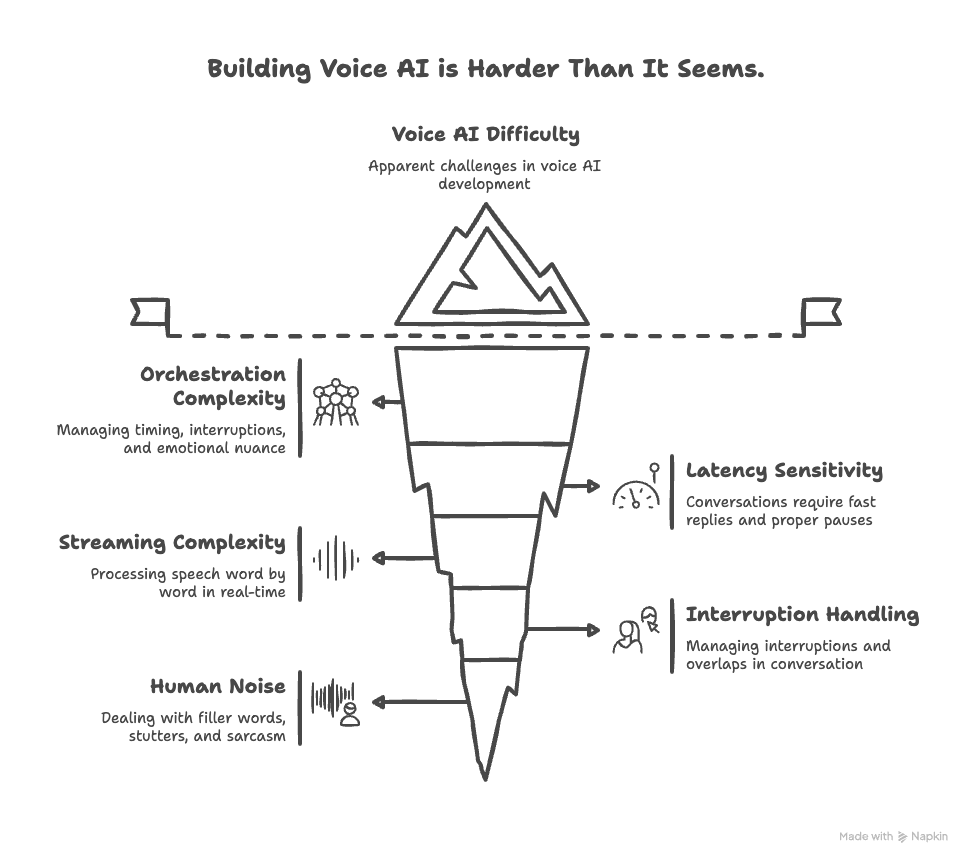
Building Voice AI is a lot like building an identity platform. The first 20% is easy and good for POC, but the remaining 80% is where everything happens.
Because it's not just about turning speech into text and spitting out a response. It's about making conversations feel right. That means managing delays, real-time interruptions, overlapping speech, context, and emotional nuance—all while staying responsive.
And this is where most off-the-shelf APIs start to crumble. They look slick in demos, but the moment they hit production—real users, real conversations—they start falling short.
This is a series of posts where we’ll break down what goes into building modern Voice AI, why APIs often don’t cut it, and what it takes to deliver an experience that truly works.
Why Voice AI is So Tough
People are unforgiving when it comes to conversational experiences. They expect fast replies, seamless turn-taking, and the ability to remember context. And the moment they suspect they’re talking to a machine, their expectations rise even higher.
Here’s what makes building for voice uniquely hard:
- Latency: A 500ms lag in an app feels fast. In a voice conversation, it’s jarring. Go beyond 1.2 seconds and it breaks the rhythm.
- Interruptions: People cut each other off. Your system needs to detect it and recover in real time.
- Streaming: Conversations don’t arrive in blocks. They unfold byte by byte. Your pipeline must work with streams.
- Messy human behavior: Users say "uhh" or backtrack mid-sentence. You need to handle false starts, corrections, and nuance on the fly.
You’re not building a chatbot. You’re building a tightly orchestrated audio-language pipeline that mimics real human speech. So experience is the key.
Core Building Blocks
Voice Activity Detection (VAD)
VAD figures out when someone is actually speaking. It’s a key part of any voice AI system—helping you cut out silence and noise so you only process real speech. This speeds things up and saves compute.
The tricky part is VAD works on confidence thresholds. If you set the threshold too strict, you'll miss the start of words. If it's too loose, background noise gets treated as speech.
But VAD is already a solved problem. Well-known libraries have taken different approaches to solve this human voice detection problem in real time.
- WebRTC VAD – Uses signal processing rules to detect human speech. It's lightweight and fast. Ideal for embedded devices but less reliable in noisy environments, especially far-field audio.
- Selerio VAD – Based on neural nets. More accurate and adaptive compared to WebRTC, especially in messy real-world audio. But computationally expensive.
At Trata AI, we use Selerio VAD with a confidence threshold of 0.9, meaning we treat any audio segment with over 90% confidence as speech. This helps maximize recall. We never want to miss human speech (false negatives). False positives are acceptable since they can be filtered later in the pipeline.
Speech-to-Text (STT)
Once VAD detects that the audio stream contains human speech, STT transcribes the audio to text. For production-grade real-time conversational AI agents, the STT provider must support streaming. Also, STT systems should be tunable, especially for recognizing industry-specific terms. Some STT providers support custom vocabularies to enhance recognition. Some call this "word boosting."
But this alone is not enough. If you ask users to share their name, address, or email, STT often gets it wrong. At Trata AI, we use techniques like asking users to spell their names. Once we capture the email or address, our AI agent spells it back to confirm. Similar to how humans do it. It's important to balance being accurate without being too verbose—so users don’t lose interest in talking with the agent.
This problem gets worse with accents. Sharp accents can cause issues. So context must be fed, and at some point, the intelligence layer should handle the shortcomings in recognition.
An ideal ASR provider should have:
- Low inference latency (< 300 ms)
- Accent handling
- Tunability to avoid false interpretations
Popular choices
- Whisper – From OpenAI. It’s open source (kudos to OpenAI), high accuracy, designed for offline transcripts. Not meant for online streaming use cases, but techniques like Whisper Streaming and Whisper-Simuli can help make it work in real time without full fine-tuning.
- Deepgram, AssemblyAI – Off-the-shelf cloud solutions. Both are solid with streaming support.
At Trata AI, we use Deepgram for speech-to-text. Their async Python SDK makes managing the orchestration easier.
Language Model (LLM)
The brain of the system. Understands user intent from the STT transcript and decides what to do next. Some pre-requisites include gathering context through RAG and storing user memory. We use RAG and Nomic embeddings to store relevant docs. They topped the MTEB leaderboard and we could run them on CPU instead of using cloud embeddings, which helps reduce latency. Every millisecond counts.
A good setup here:
- Holds both short-term and long-term context from the session start
- Responds based on emotion, hesitation, or ambiguity
- Manages flow and redirection—even mid-sentence
You can boost LLM performance by:
- Using retrieval-augmented generation (RAG)
- Designing structured prompts and fallback paths with tool calling
You can start with second-tier LLMs like Gemini Flash, 4o mini, or Llama 70B. They perform well for conversational use cases and save cost and latency. You can switch to SOTA models later based on needs.
This is often the biggest time sink in a voice AI system. How the RAG pipeline is structured and how your system talks to the LLM can save valuable milliseconds. When to invoke the LLM also matters. If you trigger it too early while the user is still speaking, you waste tokens. If too late, it adds latency. Choosing the right moment is key. We’ll go deeper on this in the next blog.
Text-to-Speech (TTS)
Once the LLM generates text, the final step is converting it to voice. Many great TTS providers support real-time text-to-speech. A good TTS must:
- Operate under 100ms
- Provide streaming support
- Maintain consistency in tone, emotion, and delivery
Leading providers like ElevenLabs, Cartesia, and Rime offer expressive, low-latency voices. Cloud providers also offer neural voices with controls.
Once VAD, STT, LLM, and TTS are in place, orchestration makes all the difference. Everything must run in parallel, recover from interruptions, and feel conversational.
The Hidden Beasts
Sentence Boundary Detection (SBD)
One of the most overlooked parts of the voice AI pipeline. Machines can’t tell if a pause means “I’m done” or “I’m thinking.” In text, "Enter" marks the boundary. In speech, it's not that simple.
Example:
User: "I’d like to book a table for four… [pause] maybe five… at 7 pm."
Act too early and you book four. Act too late and latency frustrates the user. If done right, this improves customer experience and separates great agents from average ones.
Most voice AI agents fallback to waiting 100–500ms before acting. But that adds latency. Acting too quickly means constant interruptions. Fine-tuning this is critical. At Trata AI, we use adaptive pacing and NLTK techniques to detect sentence boundaries.
Dialog Management in Streaming Voice
In text-based systems, users hit a delimiter to end the dialog. Streaming systems don’t have that. Either user or AI can barge in anytime. Everything happens now. So dialog management and client buffer control are critical.
In browser-based agents, you need to manage audio worklets and flush buffers on barge-ins to avoid overlapping speech. Telephony systems must flush only specific dialogs, not the full buffer.
You need a dialog manager that:
- Detects when users interrupt TTS
- Stops the speech
- Cancels ongoing logic
- Flushes buffers
Backchanneling vs. Hard Interruptions
You must know when to regenerate a response and when not to. Users often say “Sure” or echo what the agent said just for acknowledgment. That’s backchanneling. Not a real interruption.
Add logic to detect backchanneling vs hard interruptions. Like humans do. Solve this in real time with minimal latency.
Voice API Providers: Helpful, but Not Enough
Platforms like VAPI, Retell, and Bland are great for getting started. Huge respect for what they’ve built. They offer:
- Pre-built pipelines
- Hosted infra
- WebRTC/telephony support
But they fall short in a few areas:
- Limited control on timing: Can’t customize interruption logic.
- Latency: Hard to control. You're at the mercy of the platform.
- No session memory: Can't persist context across flows.
- Hard to debug: No access to timestamps, VAD triggers, or real-time internals.
They’re great for simple bots. But for complex use cases like multi-modal agents or concierge/roleplay systems like Trata AI, where timing and memory matter, you’ll hit limits fast.
When to Build Your Own Pipeline
You don’t always need a custom build. But you should if:
- You need session continuity and memory (like Trata AI's concierge).
- You want to control how your bot interrupts, adapts, or changes tone.
- You need low-level latency control for conversational fillers.
- You want multi-modality support.
Custom orchestrator pipelines let you:
- Fine-tune VAD thresholds
- Run domain-optimized STT
- Prompt or fine-tune your LLM
- Use expressive, controllable TTS
- Detect barge-ins vs acknowledgments
- Handle silences with proactive nudges
Yes, it’s more complex due to the latency demands. But it pays off. Your users will feel the difference and businesses will love the control and customization.
Managing Memory and Real-time Audio
Since everything is stateful and runs in real time, memory management is critical for scaling. Network protocols and audio formats greatly affect both experience and cost. Async IO-style solutions work really well.
For Trata AI, we use websockets as its universal for both browser and telephony based systems but solutions like daily co provides robust SDKs for managing the communication protocol layer.
Final Thoughts
Voice agents are not just stitched APIs. They require coordinated engineering across audio, language experience, memory, and system layers. Agents should be programmed to know must know when to listen, how to respond, and how to pace with messy human speech—in real time. API providers are improving. But when experience matters so its important to build deeper.
Coming up next: A deep dive into Sentence Boundary Detection and how we tamed latency and interruptions at Trata AI.
About Trata AI
Trata AI is a conversation intelligence and AI agent platform that helps sales and service teams analyze calls, simulate role-plays, and boost conversions through real-time feedback and coaching.
Our Concierge (Trata Answers) product acts as an AI receptionist and support agent—handling bookings, queries, and transactions across voice and chat with human-like conversations and business-specific memory.
If you're interested to know more, let’s talk. Literally!